개발자 => Spring Data JPA => JPA => JDBC => h2드라이버 => h2 DB
Database => H2
사용이유 : 개발용, 테스트용으로 용이
아래 내용을 application.properties에 적어 설정한다.
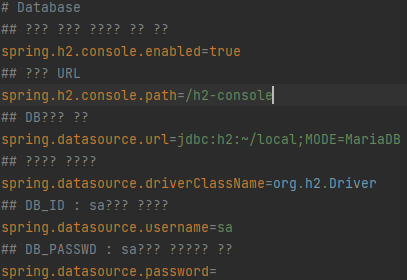
그리고 사용자의 local에 db파일을 만든다.

스프링 서버를 실행 후 localhost:8080/h2-console 에 들어가 연결 되는지 확인한다.
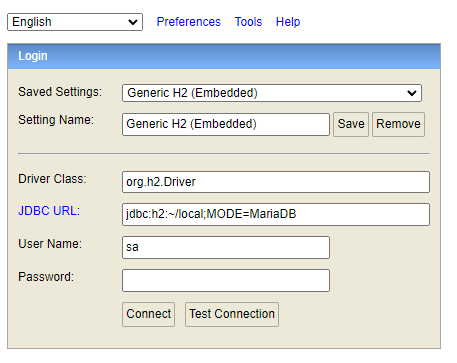
이런 창이 뜬다면 성공이다!
엔티티 생성
새로운 Entity를 생성했다.
QnA를 만들기 위해 Question, Answer Entity를 생성했는데 JPA를 사용하여 만들어 보기로 하자.
1. Question Entity
첫번째로, build.gradle에 dependency를 추가한다.

두번째로, application.properties에 설정을 저장한다.

그 후, Question class를 생성하여 만들 엔티티를 구성한다.
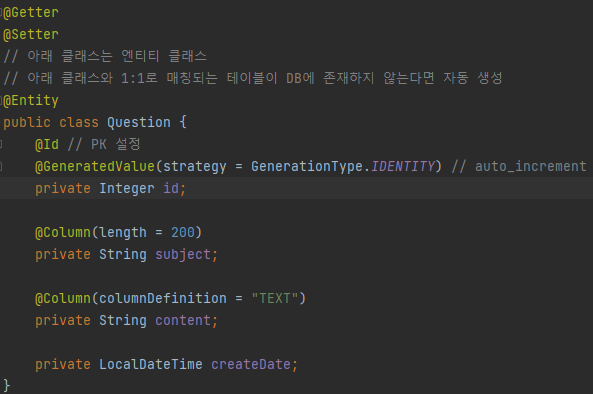
- @Entity : 엔티티 클래스라고 정의 → 존재하지 않는다면 DB에 테이블 생성
- @Id : 기본키(Primary Key)로 설정한다.
- @GeneratedValue : auto_increment를 설정한다.
- strategy는 고유번호를 생성하는 옵션으로 GenerationType.IDENTITY는 해당 컬럼만의 독립적인 시퀀스를 생성하여 번호를 증가시킬 때 사용한다. - @Column : 컬럼의 세부 설정을 위한 어노테이션.
- length : 컬럼의 길이를 정의
- columnDefinition : 컬럼의 속성을 정의
h2 console을 통해 잘 만들어졌지 확인해보자!
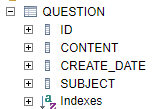
2. Answer Entity
Question Entity와 같이 class를 만들어 내용을 입력했다.
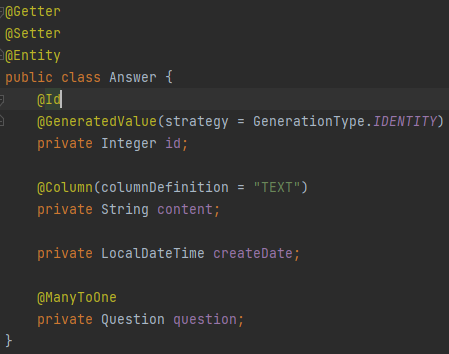
거의 비슷하지만, 맨 아래의 question은 다르다.
여기서 하나의 Question에 대한 답변이기 때문에 Question에 대한 정보를 불러와야 한다.
JAVA이기 때문에 객체로 불러올 수 있다 하지만, 데이터베이스에서는 객체를 불러올 수 없다.
그래서 JPA에서는 이것을 questionId로 의역하여 DB에 저장한다.
또한, @ManyToOne 어노테이션은 질문과 답변이 N : 1관계이기 때문에 적어야 한다.
결과는?
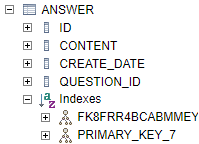
FK 제약조건까지 걸린 ANSWER이 생성되었다.
추가로 많은 답변에 대한 하나의 질문(N : 1) 관계가 될 수 있다.

mappedBy에는 Answer에 연결되어 있는 Question 객체의 이름을 적어준다.
또한 cascade는 연쇄효과를 의미하며, question이 삭제될 경우 답변들 모두가 함께 삭제된다.
레포지토리 생성
레포지토리 생성할 경우 interface로 생성해야 한다. 또한 JpaRepository 를 상속해주고, 제너릭 내에는 클래스와, pk의 자료형을 적어준다.
Question Entity의 Repository이다.

Answer Entity의 Repository이다.

그 후 질문 저장이 잘 되는가에 대해 확인하기 위해 TDD를 활용하여 TEST를 진행했다.

JPA로 H2 Database에 넣어보았다.
"H2 데이터베이스는 파일 기반의 데이터베이스이기 때문에 이미 로컬서버가 점유하고 있기 때문에 오류가 발생하는 것이다. 따라서 테스트를 하기 위해서는 로컬 서버를 중지해야 한다." 라는 주의사항이 있고, 오류가 발생하지 않게 서버를 종료 후 실행해보았다.
결과는 잘 나왔다!
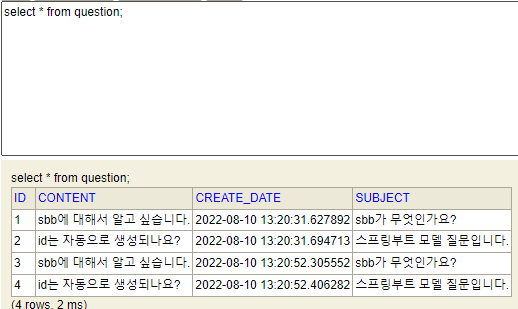
보면 ORM 형식으로 설정한 Database에 값을 넣을 수 있다는 것이 굉장히 신기했고, SQL문을 사용하지 않아도 되서 너무 편리했다.
전체 게시물 찾기
findAll을 통해 select * from question 과 같은 쿼리문을 실행시킨다.
Test를 위해 TDD를 사용하여 진행했다.
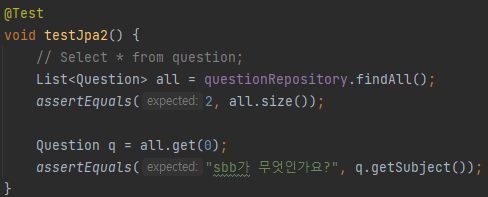
이도 마찬가지로 서버를 종료 후 실행해야 한다.
Test결과는 성공적이다. 데이터베이스 내 총 size는 테스트로 만든 2개의 질문이고, 리스트에 담은 Question객체의 첫번째 객체를 가져와 getSubject를 이용해 subject에 대한 내용과 비교했을 때 정확하게 맞아 떨어져 성공했다.

하나의 게시물 찾기(ID를 통해)
전체 게시물을 찾기 위해 findById를 사용하였다. 하지만, findById 메서드는 Question 객체가 아닌 Optional 객체를 반환한다. Optional은 null처리를 유연하게 하기 위해 사용하는 클래스로써 isPresent 메서드를 사용해 존재하는지 확인 후 get을 통해 실제 Question 객체를 반환한다.
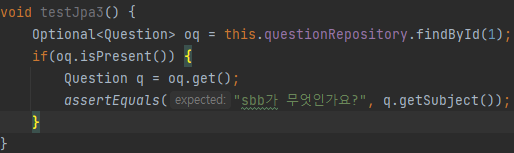
성공적으로 실행되었다.

하나의 게시물 찾기(subject를 통해)
인터페이스에 findBySubject 메서드를 만든다.

QuestionRepository 객체가 가 생성될 때 DI에 의해 스프링이 자동으로 QuestionRepository 객체를 생성하고, 객체의 findBySubject가 실행될 때 JPA가 해당 메서드명을 분석해 쿼리를 만들고 실행하기 때문에 메서드 구현을 하지 않아도 실행된다.
테스트 결과는?

아주 성공적이다.
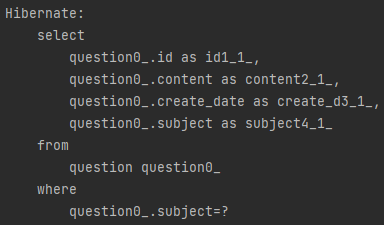
Repository 안의 메서드가 어떻게 자동으로 분석되어 진행되는지 쿼리문이 어떻게 작성되는지 알고 싶어 확인하기 위해 설정을 변경해 주었다.
application.properties에

두개의 코드를 넣어주고, 다시 테스트 코드를 실행한다.
그러면 쿼리문이 어떻게 작성되는지에 대해 출력된다!
하나의 게시물 찾기(subject와 content를 통해)
subject를 이용해 찾았던 것 처럼 subject + content를 통해 게시물을 찾아보자.
위와 같이 Repository에 메서드를 넣어주고

바로 해당 메서드를 사용한 test를 진행했다.
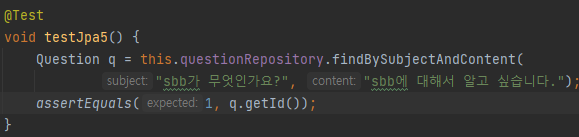
결과는 아주 잘 나왔고
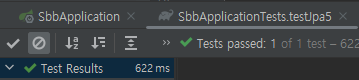
where절에 and를 사용하여 2개의 컬럼값을 통해 찾아내었다.
+ 여기서 and만 가능할까?
아니다. 메서드 명을 변경하여 AND OR Between A and B 등.. 여러가지를 사용할 수 있다. 근데 여러개의 결과값이 나온다면 List, 단일 결과값이 나온다면 객체 자체를 반환해주는 것이 가장 좋다.
++ 근데 왜 id만 Optional 객체를 반환할까?
내 생각에는 Subject나 다른 컬럼들은 존재할 수 있지만, id는 primary key 이기 때문에 유일한 값이다. 그러므로 null값이 존재할 가능성이 크기 때문에 Optional 객체를 반환 후 null값인지 아닌지를 체크해 Question 객체로 다시 반환해주는 것이지 않을까 한다.
여러개의 게시물 찾기(특정 문자열이 포함되어 있는지를 통해)
%를 통해 특정 문자열이 포함되어 있는 게시물들을 다 가져온다.
여러개의 게시물을 포함할 수 있기 때문에 하나의 객체로 불러오는 것이 아닌, List 형태로 반환한다.
위와 마찬가지로 Repository class에 메서드를 넣고

지정한 특정 문자열을 포함한 객체를 모은 List를 가져온다.
그 후 get을 통해 원하는 index의 객체를 Question 객체로 반환 후 비교하는 테스트를 거친다.
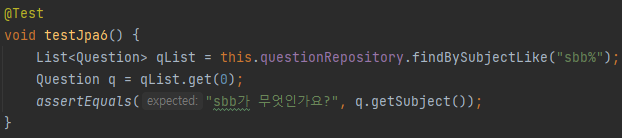
결과는 잘 나왔다.
데이터 수정하기
데이터를 수정하기 위해서는 update문을 어떻게 사용해야 할까?
원하는 변수에 set을 사용해주면 된다. 원하는 게시물을 불러와 변경하고자 하는 제목을 setSubject 메서드를 실행하여 수정할 수 있다. 하지만, 수정을 저장해주기 위해 다시 Repository의 JpaRepository에 포함되어 있는 save 메서드를 실행시켜주어야 한다.

수정을 시키는 쿼리문은
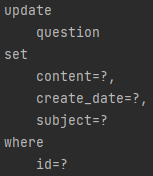
으로 출력되었고, 정상적으로 잘 변경되었다.

데이터 삭제하기
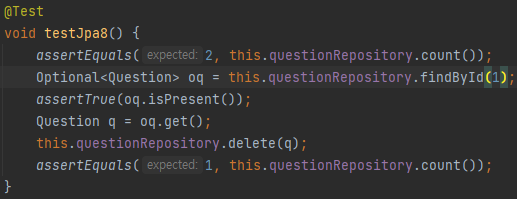
findById를 통해 id값을 통해Optional 객체로 가져오고, null값이 있는지 없는지 확인 후 Question 객체로 반환해준다.
그 후 JpaRepository의 기본 메서드인 delete를 실행하여 데이터를 삭제한다.
삭제를 시키는 쿼리문은

로 진행되고, 결과는 id가 1번인 게시물이 삭제된다.

답변 데이터 생성 후 저장하기
Answer 객체를 만들어주기 위해 QuestionRepository와 같이 선언해준다.

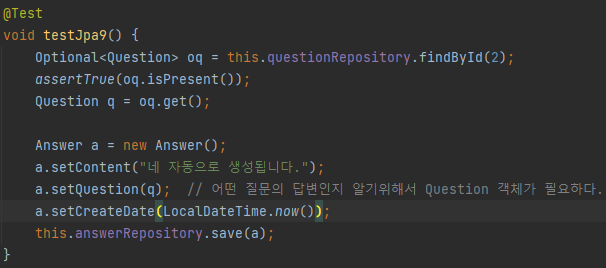
그 후 원하는 Question에 대한 답변을 위해 findById를 통해 Question 객체를 불러오고, null인지 아닌지 확인한다.
Answer이라는 객체 생성 후, setter을 통해 Answer 객체에 데이터를 넣어준다.
그리고 JpaRepository 객체에서 상속받은 save를 통해 저장한다.
테스트는 잘 실행되고,
쿼리문은
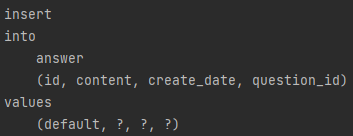
결과는로 잘 나온다!!

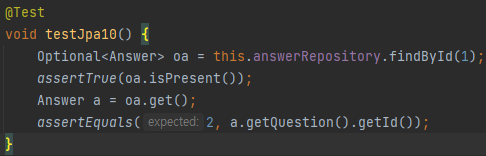
답변 데이터 조회하기
findById를 통해 Answer 객체를 Optional로 받아와 null인지 아닌지를 체크하고 Answer객체로 반환한다.
그리고 답변에 대한 Question 객체의 id값과 비교한다. Answer에 대한 Question 객체를 넣어놨기 때문에 가져올 수 있다.
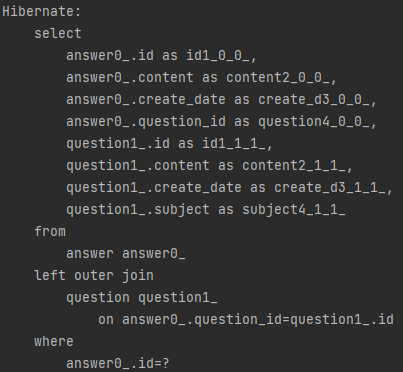
실행된 쿼리문을 확인해보자.
여기서 보면 Question 객체까지 가져와야 하기 때문에 join문을 사용하였다.
질문에 달린 답변 찾기
답변에 달린 질문을 찾으려면 getQuestion 메서드를 사용하면 된다.
그러면 질문속에서 답변을 찾을 수 있는 방법이 있을까?
아까 Entity에서 정의한

를 사용하면 될 것 같다.
질문들 중에서 findById를 통해 하나의 질문을 가져오고, 그 질문에 대한 답변들을 List로 불러올 수 있다.
mappedBy을 통해 적은 question을 통해 연결되어 있는 하나의 Question 객체가 Answer들의 정보를 알 수 있게 된다.
그래서 getAnswerList를 통해 Answer객체의 정보들을 가져와 List로 반환하여 저장한다.
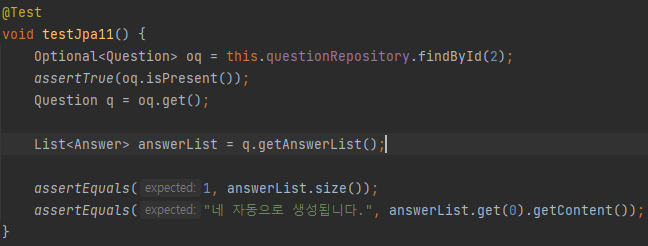
하지만 오류가 발생하게 되는데,

이유는 findById를 호출하여 객체를 조회하면 DB와의 세션이 종료되기 때문이라고 한다. 그래서 getAnswerList의 메서드가 실행되지 않아 조회할수가 없다.
++ 이것은 테스트 코드에서만 발생하는 오류일뿐 실제 JPA 프로그램을 실행할 때는 DB세션이 종료되지 않기 때문에 오류가 발생하지 않는다.
해결하기 위해서는 @Transactional 어노테이션을 사용한다.
→ 메서드가 종료될 때 까지 DB 세션 유지

그 후 실행하면 성공적으로 실행된다.

'Spring' 카테고리의 다른 글
| [Spring]Spring 시작해보기(6) - Thymeleaf를 사용해 QuestionList 출력 (0) | 2022.08.16 |
|---|---|
| [Spring]Spring 시작해보기(5) - MariaDB의 Truncate Table 실행하기 (0) | 2022.08.11 |
| [Spring]Spring 시작해보기(4) - H2 데이터 베이스에서 MariaDB로 변경(JPA) (0) | 2022.08.11 |
| [Spring]Spring 시작해보기(2) - CRUD (0) | 2022.08.09 |
| [Spring]Spring 시작해보기 - Setting / Mapping / Session (0) | 2022.08.08 |



